그룹 함수(GROUP FUNCTION)
하나의 테이블을 여러 번 읽어 재정렬하지 않고, 하나의 SQL로 테이블을 한 번만 읽어서 빠르게 원하는 리포트를 작성.
→ 집계 함수(COUNT, SUM, AVG, MAX, MIN)를 제외한 ROLLUP, CUBE, GROUPING SETS
- ROLLUP 함수
소그룹 간의 소계 계산.
Subtotal Level: N + 1
ex) GROUP BY ROLLUP (A, B);
→ Grouping Columns의 수: 2개 (A와 B)
→ Subtotal Level : 3 (2 + 1)
- CUBE 함수
GROUP BY 항목들 간 다차원적인 소계 계산.
Subtotal Level: 2의 N승
ex) GROUP BY CUBE (A, B);
→ Subtotal Level : 4 (2의 2승)
- GROUPING SETS 함수
특정 항목에 대한 소계 계산.
GROUP BY
| ROLLUP (A, B) | CUBE (A, B) | GROUPING SETS (A, B) | |
| L1 | A, B에 대한 집계 | A, B에 대한 집계 | 각 A에 대한 B의 소계 |
| L2 | 각 A에 대한 B의 소계 | 각 A에 대한 B의 소계 | 각 B에 대한 A의 소계 |
| L3 | 전체 집계 | 각 B에 대한 A의 소계 | |
| L4 | 전체 집계 |
※ ROLLUP, CUBE, GROUPING SETS 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 정렬 칼럼을 명시해야 한다.
1) ROLLUP 함수
ROLLUP에 지정된 Grouping Columns의 List는 Subtotal을 생성하기 위해 사용됨.
- ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀜.
- 결과에 대한 정렬이 필요한 경우 ORDER BY
ROLLUP 함수 사용
[예제] 부서명(DNAME)과 업무명(JOB)을 기준으로 집계한 GROUP BY SQL 문장에 ROLLUP 함수를 사용하여 소그룹 간 소계를 계산한다.
SELECT DNAME, JOB,
COUNT(*) "TOTAL Empl",
SUM(SAL) "TOTAL Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
[실행 결과]
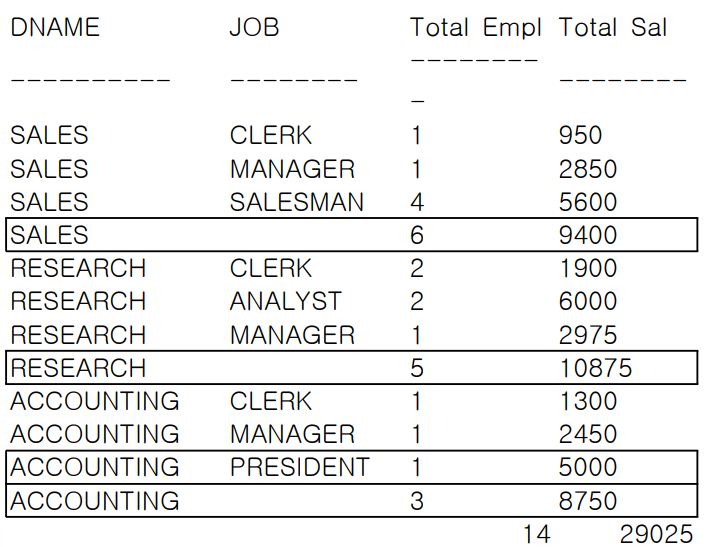
L1 - GROUP BY 수행 시 생성되는 표준 집계 (9건)
L2 - DNAME 별 모든 JOB의 SUBTOTAL (3건)
L3 - GRAND TOTAL (마지막 행, 1건)
ROLLUP의 원리
GROUP BY ROLLUP (DNAME, JOB);GROUP의 개수: 3개
→ ① DNAME, JOB
→ ② DNAME
→ ③ 전체에 대한 결과
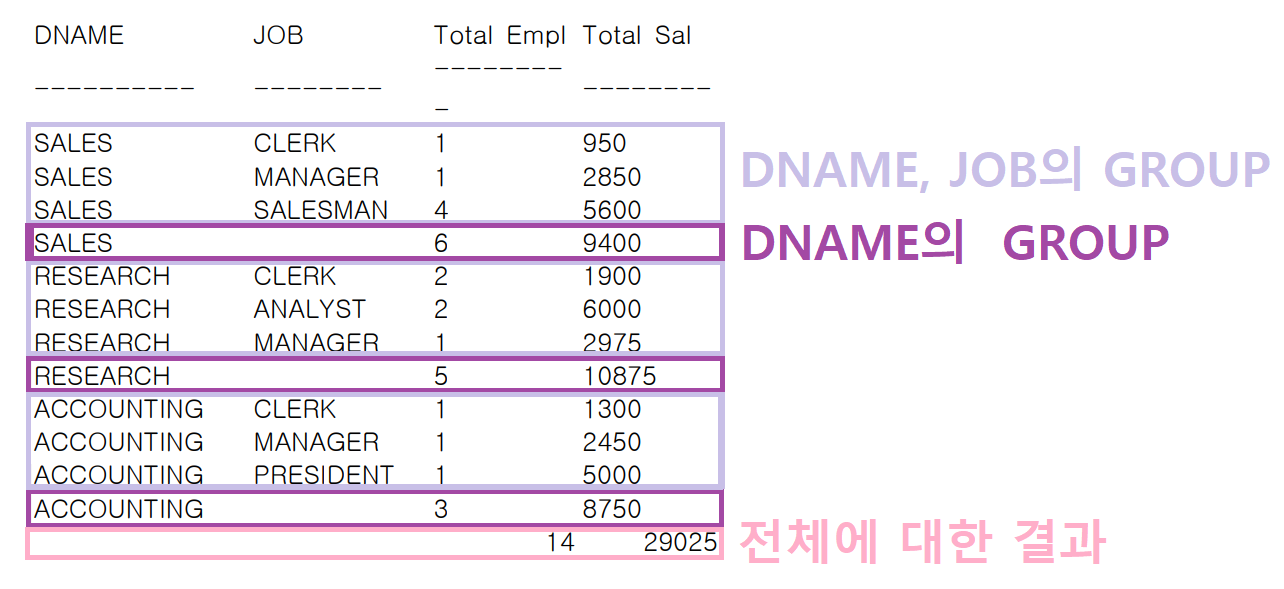
ROLLUP의 경우 계층 간 집계에 대해서는 LEVEL 별 순서를 정렬하지만(L1 → L2 → L3)
계층 내 GROUP BY 수행 시 생성되는 표준 집계에는 별도의 정렬을 지원하지 않는다.
→ ORDER BY 절을 사용해야 한다.
ROLLUP의 원리
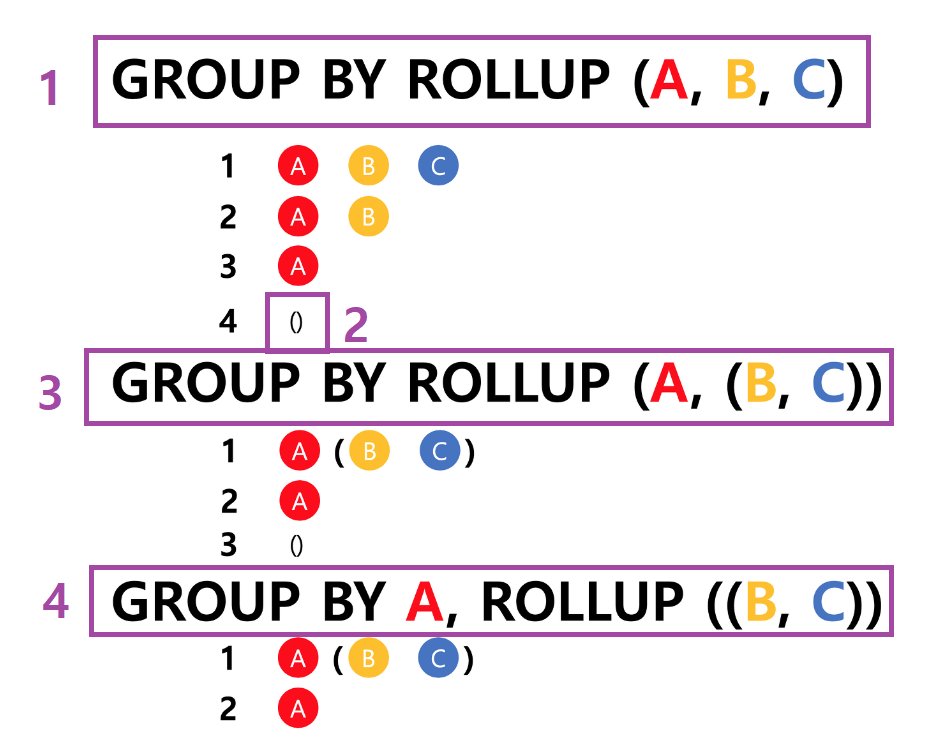
1. ROLLUP의 인자로 들어온 칼럼을 오른쪽부터 하나씩 빼면서 GROUP을 만든다.
2. "()"의 의미는 GROUP이 없는 전체에 대한 결과를 출력한다는 것이다.
3. 괄호로 묶여져 있는 칼럼은 하나로 본다는 것이다.
4. ROLLUP 이전에 일반 컬럼과 GROUP BY 한다면, 일반 컬럼은 끝까지 남는다.
출처 ↓
2) CUBE 함수
결합 가능한 모든 값에 대하여 다차원 집계를 생성.
- 인수들 간 계층 구조인 ROLLUP과 달리 평등한 관계.
→ 인수 순서가 바뀌어도 결과는 동일.
- 결과에 대한 정렬이 필요한 경우 ORDER BY
- Grouping Columns이 가질 수 있는 모든 경우에 대하여 Subtotal을 생성해야 할 경우 사용.
→ ROLLUP에 비해 시스템에 많은 부담을 줌
CUBE + GROUPING 함수 사용
- CUBE에 의한 소계가 계산된 결과에 GROUPING(EXPR) = 1이 표시
- 예제에서는 GROUPING(EXPR) = 1 일 때, 각각 'All Departments' 와 'All Jobs'가 출력.
[예제]
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB);
[실행 결과] ROLLUP 함수의 결과 + 업무별 집계(5건)

L1 - GROUP BY 수행 시 생성되는 표준 집계 (9건)
L2 - DNAME 별 모든 JOB의 SUBTOTAL (3건)
L3 - 모든 DNAME의 SUBTOTAL (5건)
→ All Departments - CLERK, ANALYST, MANAGER, SALESMAN, PRESIDENT 별 집계 추가 (5건)
L4 - GRAND TOTAL (1건)
3) GROUPING SETS 함수
GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있다.
- 인수들 간 계층 구조인 ROLLUP과 달리 평등한 관계.
→ 인수 순서가 바뀌어도 결과는 동일.
- 결과에 대한 정렬이 필요한 경우 ORDER BY
[일반 그룹함수 예제] 부서별, JOB별 인원수와 급여 합.
SELECT DNAME, 'All Jobs' JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments' DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPTNO = EMP.DEPTNO
GROUP BY JOB;
[일반 그룹함수 실행 결과]

[GROUPING SETS 예제]
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);
[GROUPING SETS 실행 결과]
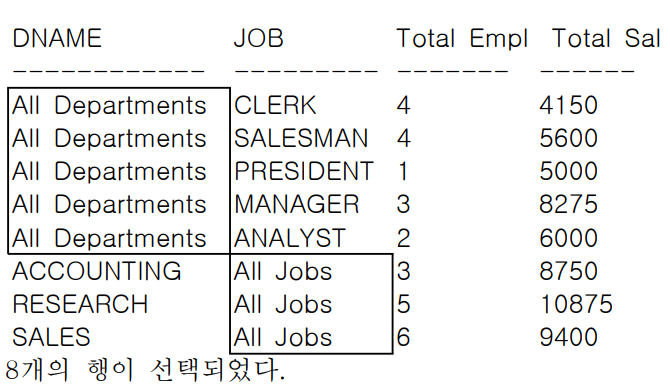
- 괄호로 묶은 집합(DNAME, JOB) 별로 집계를 구할 수 있다.
- 일반 그룹함수를 이용한 결과와 데이터는 같지만 행들의 정렬 순서가 다를 수 있다.
'데이터베이스 > 데이터베이스 공부' 카테고리의 다른 글
| 그룹 내 행 순서 함수(FIRST_VALUE, LAST_VALUE, LAG, LEAD) (0) | 2022.09.03 |
|---|---|
| 그룹 내 순위 함수(RANK, DENSE_RANK, ROW_NUMBER) (0) | 2022.09.03 |
| 뷰(VIEW, VIEW 장점, VIEW 생성, VIEW 사용, VIEW 제거) (0) | 2022.09.03 |
| FROM절 JOIN(INNER JOIN, NATURAL JOIN, USING 조건절, ON 조건절, CROSS JOIN, OUTER JOIN) (0) | 2022.09.03 |
| 일반 집합 연산자, 순수 관계 연산자 (0) | 2022.09.03 |